Compétence 4
Gérer des données de l'information
| Élément | Contenu détaillé |
|---|---|
| SAÉ concernée |
S1.04 – Gestion d’un club de voile (Base de données) Problématique : proposer une solution numérique pour gérer les inscriptions au club, la création et la validation des licences, ainsi que la gestion des équipements. |
| Sujet étudié | Analyse du besoin métier pour l’« Inscription au club »: automatiser l’appel aux cotisations, la gestion des adhérents (membres principaux et famille), le calcul des montants (type de licence, prestations supplémentaires), et la validation électronique. |
| Livrables remis |
1. Analyse fonctionnelle mise à jour :
descriptif pour solution numérique, entités, attributs, associations. 2. Modèle Entité/Association (MCD) : tables entités–relations validées, cardinalités, règles métier. 3. Modèle relationnel (MLD) : décomposition du MCD en tables normalisées (3NF), clés primaires/étrangères. 4. Scripts SQL de création : requêtes CREATE TABLE, contraintes d’intégrité, index. 5. Peuplement de la base : INSERTs d’exemples pour membres, licences, cotisations, équipements. 6. Modèle EER MySQL Workbench (export PNG) : capture des diagrammes, légende des relations. |
| Équipe | Groupe de 2 : Ahmed Errebache & Adam Choujaa. |
| Rôle personnel (Ahmed) |
• Rédaction de l’analyse grammaticale et mise à jour du descriptif. • Conception du MCD et du MLD (modélisation UML, code couleur des entités/attributs). • Écriture des scripts SQL (CREATE TABLE, INSERT, contraintes d’intégrité). • Réalisation de l’EER sous MySQL Workbench et export des diagrammes. • Coordination des réunions via Google Docs et Discord, relecture critique des livrables. • Synthèse finale et présentation orale. |
| Regard critique |
Point fort majeur :
la modélisation détaillée du processus « Inscription au club » a permis d’anticiper toutes les règles métier (licences familiales, calcul de cotisations, gestion des rappels). Limite principale : le sujet original n’était pas assez précis sur le périmètre (partie « inscription » vs « gestion des stages »), ce qui nous a contraints à redéfinir nous-mêmes les bornes du module lors de l’étape d’analyse. |
2. Apprentissages critiques (AC) mobilisés
(Compétence 4 – Gérer des données de l’information)
Mobilisé : Oui Niveau auto-évalué : Maîtrise
Commentaire :
Les requêtes SQL (INSERT/SELECT/UPDATE/DELETE) ont été exécutées sans erreur majeure. J’ai optimisé quelques jointures pour accélérer les temps de réponse, et je suis à l’aise pour construire des requêtes complexes.
Mobilisé : Oui Niveau auto-évalué : En progrès
Commentaire :
J’ai commencé à produire des graphiques descriptifs avec Python pour illustrer l’évolution des indicateurs, mais certaines visualisations manquent encore de clarté : je dois approfondir mes compétences sur Matplotlib pour enrichir mes analyses.
Mobilisé : Oui Niveau auto-évalué : Maîtrise
Commentaire :
La modélisation (MCD/MLD) a été correctement formulée, mais le sujet manquait parfois de précision : j’ai dû lever certaines ambigüités avec l’enseignant pour bien structurer les entités et les relations.
Mobilisé : Partiellement Niveau auto-évalué : En progrès
Commentaire :
J’ai commencé à fusionner plusieurs sources (CSV, bases externes), mais j’ai encore des difficultés à automatiser le traitement des imports/exports : je dois améliorer mes scripts Python pour gérer ces échanges de façon fluide.
3. Ressources mobilisées
(Compétence 4 – Gérer des données de l’information)
Semestre 1
R1.05 – Introduction aux BD & SQL
Apports : Concepts fondamentaux : DDL, DML, schéma relationnel, contraintes d’intégrité.
Mobilisation : Création des tables « Adhérents », « Licences », « Cotisations », « Équipements » pour S1.04.
R1.06 – Maths discrètes
Apports : Théorie des ensembles, cardinalités, relations, normes de normalisation.
Mobilisation : Analyse des cardinalités 1–N et N–N pour modéliser le MCD en S1.04.
R1.09 – Économie durable & numérique
Apports : Enjeux économiques du stockage de données, coûts d’exploitation, cycles de vie.
Mobilisation : Choix responsable de MySQL (open-source, faible empreinte) pour S1.04.
R1.06 (suite) – Exploitation d’une BD
Apports : Requêtes avancées : JOIN, sous‐requêtes, vues, indexation.
Mobilisation : Création de vues pour restituer l’ensemble adhérents + licences + cotisations.
R1.08 – Gestion de projet & organisations
Apports : Cycle de vie projet : planification, méthodes agiles vs classiques.
Mobilisation : Établissement du planning S1.04 sur Google Docs et coordination Discord.
R1.10 – Anglais d’entreprise
Apports : Vocabulaire technique : CRUD, SELECT, JOIN, intégrité référentielle.
Mobilisation : Lecture de la documentation MySQL en anglais pour rédiger les scripts SQL.
R1.11 – Communication
Apports : Techniques de rédaction et d’entretien, structuration de la synthèse.
Mobilisation : Rédaction critique de l’analyse fonctionnelle, relecture mutuelle.
Semestre 2
R2.06 – Outils numériques pour les stats
Apports : Python : pandas, matplotlib, visualisations exploratoires.
Mobilisation : Création de courbes KDE, boxplots et ECDF pour S2.04 (LocationAuto).
R2.08 – Exploitation d’une BD avancée
Apports : Triggers, procédures stockées, optimisation de requêtes MySQL.
Mobilisation : Implémentation de triggers pour mise à jour automatique du statut et facturation.
R2.10 – Gestion de projet & organisations
Apports : Trello Kanban, planning Gantt, réunions hebdo.
Mobilisation : Suivi du sprint S2.04, stand‐ups et mises à jour du Gantt.
4. Implication & déroulement
(Compétence 4 – Gérer des données de l’information)
SAÉ S1.04 – Gestion d’un club de voile (Base de données)
Pour cette SAÉ, Adam et Moi ont collaboré via Google Docs pour rédiger l’analyse fonctionnelle et Discord pour échanger en temps réel. J’ai assuré la majeure partie :
- Analyse métier : Définition précise des entités (Adhérents, Licences, Cotisations, Équipements), rédaction du cahier des charges descriptif.
- Modélisation : Conception du MCD et du MLD ; choix des cardinalités basé sur les exigences ;
- SQL : Rédaction des scripts CREATE TABLE, INSERT ; gestion des contraintes d’intégrité ;
- Diagrammes : Création du modèle EER dans MySQL Workbench, export PNG pour la synthèse.
Livrables finaux :
• Analyse fonctionnelle (Google Docs partagé)
• MCD + MLD (UML imprimé et export PNG)
• Scripts SQL (fichier club_voile.sql)
• Peuplement exemple (INSERT d’extraits de 50 adhérents)
• Diagramme EER MySQL Workbench (PNG joint)
• Présentation orale (diaporama + explication du schéma)
- Point fort : Modélisation complète anticipant toutes les règles métier (licences familiales, calcul automatique des cotisations, rappels de paiement).
- Limite : Le sujet initial était peu précis sur la portée (inscriptions vs gestion des stages), nous avons dû redéfinir nous-mêmes le périmètre en réunion.
5. Analyse des apprentissages
(Compétence 4 – Gérer des données de l’information)
Retour réflexif sur mes apprentissages
Au fil des deux semestres, j’ai progressivement consolidé ma maîtrise de la gestion des données. En S1, la phase d’analyse fonctionnelle m’a permis de passer d’un cahier des charges textuel à un schéma logique cohérent : j’ai compris comment identifier chaque entité métier (adhérent, licence, cotisation, équipement) et traduire leurs relations en cardinalités claires. La mise en place du MCD/MLD a renforcé ma capacité à formuler les règles métier sous forme d’attributs et de contraintes, ce qui, jusque-là, me semblait abstrait.
Lorsque j’ai rédigé les scripts SQL en S1, j’ai appris à gérer l’intégrité référentielle : définir les clés primaires/étrangères, imposer des UNIQUE sur les numéros de licence, et prévoir des déclencheurs (triggers) pour l’exécution automatique des rappels de cotisation. Cette étape a été déterminante : j’ai compris l’importance de l’unicité des données et des dépendances, et j’ai gagné en confiance pour écrire des requêtes CREATE TABLE et INSERT complexes sans erreurs.
En S2, l’introduction des triggers MySQL et des procédures stockées m’a propulsé vers un niveau supérieur : j’ai dû automatiser la génération de factures et la mise à jour du statut des véhicules lors de la location/retour. J’ai appris à écrire un trigger “AFTER INSERT” qui crée immédiatement une facture dès qu’un contrat est validé. J’ai pris conscience qu’une base de données relationnelle ne se limite pas à stocker des données, mais peut aussi encapsuler la logique métier, garantissant une fiabilité en temps réel.
L’aspect mathématique couplé à l’extraction de statistiques en Python m’a permis d’aborder la partie “visualisation” : j’ai construit des KDE pour analyser la répartition des durées de location, généré des boxplots pour détecter les valeurs aberrantes (kilométrages excessifs) et élaboré des ECDF pour comprendre la dispersion des revenus. J’ai compris que l’étape d’extraction des données (SELECT, JOIN, VIEW) conditionne la qualité des graphiques, et j’ai progressivement affiné mes requêtes pour obtenir des datasets propres à chaque analyse.
Globalement, j’ai constaté que :
- Mon point fort : la modélisation conceptuelle et logique : je parviens désormais à bâtir un MCD/MLD exhaustif sans devoir revenir plusieurs fois vers les exigences.
- À améliorer : l’automatisation complète des imports/exports (gestion de données hétérogènes) reste perfectible : je dois approfondir mes compétences en scripting Python pour gérer plus efficacement les échanges CSV → MySQL et réciproquement.
Leçon tirée :
La maîtrise d’une base relationnelle ne s’arrête pas à la création de tables : il faut penser à
déclencher des vérifications automatiques (triggers) et prévoir des vues/indices pour optimiser
les requêtes d’analyse.
6. Axes d’amélioration
(Compétence 4 – Gérer des données de l’information)
Semestre 1 : J’ai rencontré des difficultés pour comprendre le sujet donné (gestion du club de voile). Les consignes manquaient parfois de précision sur le périmètre fonctionnel (inscription seule ou stage ?).
Semestre 2 : La partie mathématique (analyse statistique) s’est avérée complexe : j’ai dû jongler entre Python et SQL pour produire les courbes appropriées.
Retour professeur : Le professeur Fahed Abdallah a validé la partie informatique. En mathématiques, l’enseignant Patrick Adelbrecht a recommandé d’ajouter un volume de données plus conséquent (plusieurs centaines d’exemples) afin d’obtenir des visualisations statistiques plus pertinentes.
→ À améliorer : clarifier le sujet dès le départ (périmètre précis) et enrichir les ensembles de test mathématiques pour renforcer la crédibilité des graphiques.
Semestre 1 : Pendant chaque séance dédiée à la SAÉ, je me sentais parfois hors sujet et manquais de motivation, ce qui ralentissait la rédaction et la validation des requêtes de création/consultation.
Semestre 2 : La partie info s’est déroulée sans blocage majeur ; en revanche, l’idée de devoir présenter en anglais m’a mis sous pression : je passais du temps à reformuler mes requêtes pour qu’elles soient compréhensibles lors du pitch.
→ À améliorer : adapter un planning plus serré pour réserver du temps à la rédaction des requêtes avant chaque séance, et s’entraîner à présenter techniquement en anglais pour être plus fluide.
Point d’amélioration général : J’ai commencé à créer des triggers et des procédures stockées pour automatiser la mise à jour des statuts et la génération de factures, mais certains scénarios (mise à jour simultanée des tables, verrouillage) ont entraîné des erreurs de transaction.
Cas concret : Sous MySQL, lorsque deux inserts simultanés visaient la même table “Paiements”, le trigger ne s’exécutait pas systématiquement dans l’ordre souhaité. J’ai donc dû ajouter des contrôles de version et repenser la logique conditionnelle.
→ À améliorer : approfondir la gestion des transactions SQL (COMMIT/ROLLBACK) et tester chaque trigger sur de grands jeux de données pour anticiper les blocages verrouillage.
Observations : Les graphiques descriptifs (histogrammes, boxplots, ECDF) étaient corrects, mais certaines visualisations manquaient de lisibilité (axes mal calibrés, légendes absentes).
→ À améliorer : standardiser le format des graphiques (titres, légendes, annotations) et ajouter des commentaires explicatifs dans le notebook pour guider le lecteur.
Force : J’ai rédigé un README détaillé pour chaque script SQL (création, peuplement, triggers) et annoté les notebooks Python. Les intermembres pouvaient comprendre le flux global.
Limite : Cependant, la cohérence entre les versions SQL et le notebook Python n’était pas toujours explicitée : il manquait un chapeau “comment exécuter d’abord le DDL puis importer le CSV”.
→ À améliorer : ajouter un guide pas-à-pas (install.sh ou Makefile) pour cloner le dépôt, lancer les scripts SQL, puis exécuter le notebook sans intervention manuelle.
Semestre 1 : Adam et moi avons utilisé Google Docs et Discord pour communiquer, mais les versions de notre MCD/MLD n’étaient pas toujours synchronisées ; nous avons parfois travaillé sur des copies locales.
Semestre 2 : Lucas et moi avons versionné les scripts SQL sur GitHub, mais nous avons manqué de conventions de commit (messages trop vagues) et de branches dédiées pour les tests Python.
→ À améliorer : établir une règle de commit claire (type Conventional Commits), créer des branches “feature/statistiques” et “feature/ddl” pour isoler le développement, et fixer un rendez-vous Git bihebdomadaire pour synchroniser.
7. Traces choisies
(Compétence 4 – Gérer des données de l’information)
Trace 1 : Rendu complet SAE 1.04 (PDF)
Commentaire : Ce document illustre l’ensemble de la modélisation du club de voile : MCD, MLD, scripts SQL et captures MySQL Workbench.
Trace 2 : Extrait SQL (SAE 2.04 – Info)
-- Déclencheurs `contrat`
DELIMITER $$
CREATE TRIGGER `trg_contrat_after_insert` AFTER INSERT ON `contrat` FOR EACH ROW BEGIN
UPDATE vehicule
SET status = 'Rented'
WHERE id_vehicule = NEW.id_vehicule;
END
$$
DELIMITER ;
--------------------------------------------------------------------------------------
DELIMITER $$
CREATE TRIGGER `trg_contrat_after_update` AFTER UPDATE ON `contrat` FOR EACH ROW BEGIN
IF OLD.end_date <> NEW.end_date AND NEW.end_date <= CURDATE() THEN
UPDATE vehicule
SET status = 'Available'
WHERE id_vehicule = NEW.id_vehicule;
END IF;
END
$$
DELIMITER ;
Commentaire : Extrait du code SQL des triggers utilisés pour automatiser la mise à jour du statut des véhicules.
Trace 3 : Graphiques statistiques (SAE 2.04 – Maths)
Commentaire : Ces graphiques illustrent l’analyse descriptive : distribution des kilométrages, dispersion des tarifs et ECDF des durées.
Trace 4 : Capture MySQL Workbench (Diagramme EER)
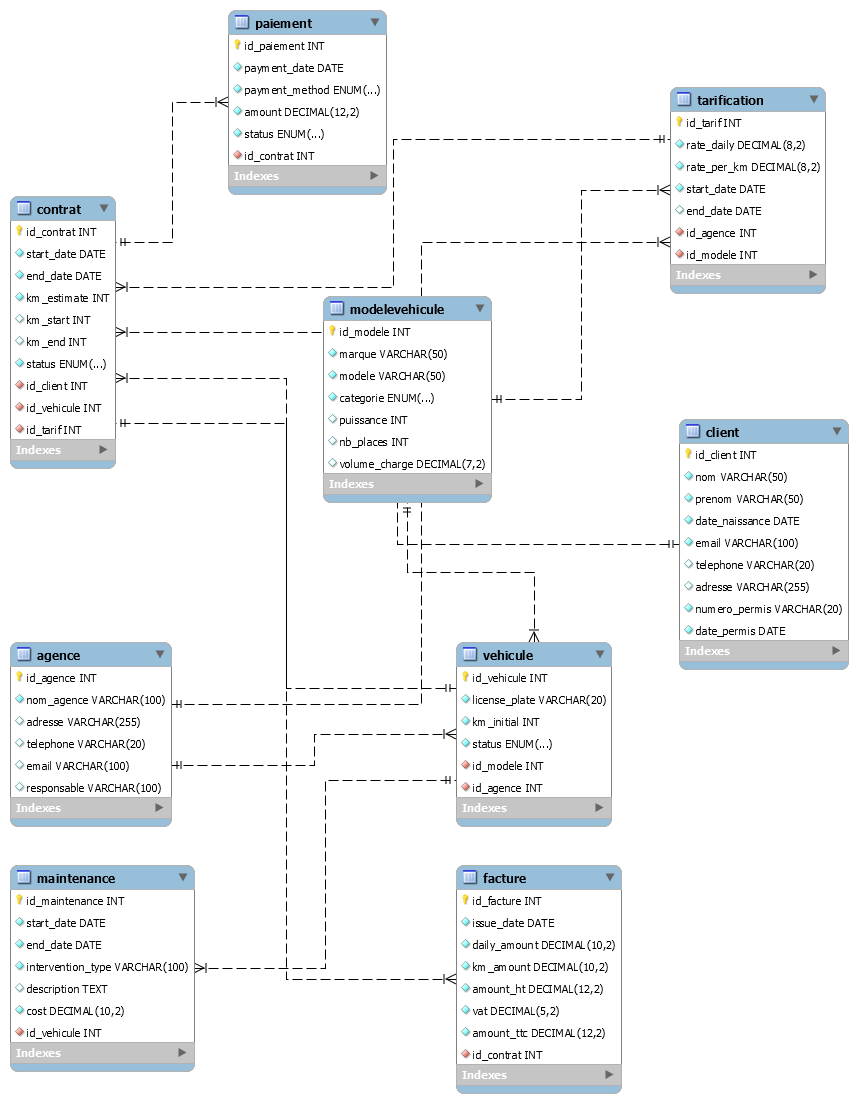
Commentaire : Schéma complet de la base « LocationAuto » sous MySQL Workbench.
Trace 5 : Capture MCD (SAE 1.04)

Commentaire : Extrait du MCD réalisé pour la gestion du club, montrant les entités et leurs relations.
8. Originalité & qualité
(Compétence 4 – Gérer des données de l’information)
Synthèse de l’originalité et de la qualité
-
Approche originale (S1) :
- Le MCD « Club de Voile » intègre un code couleur pour distinguer les entités principales (membres, licences, équipements) – favorisant la clarté visuelle.
- La modélisation a été affinée par l’ajout de règles métier inédites (licences familiales combinées, calcul automatique des rappels), montrant une réflexion au-delà du simple cahier des charges.
-
Qualité des livrables (S1) :
- Les scripts SQL sont commentés et normalisés : chaque CREATE TABLE inclut une description de champ, facilitant la maintenance.
- L’export PNG du modèle EER intègre la légende des cardinalités directement sur le diagramme, évitant toute confusion.
-
Approche originale (S2) :
- Combinaison SQL + Python : non seulement la base de données est robuste, mais les analyses statistiques (KDE, boxplots, ECDF) mettent en lumière des indicateurs métiers pertinents (durée moyenne de location, pics saisonniers).
- Les triggers MySQL sont conçus pour générer automatiquement des factures et mettre à jour le statut des véhicules, démontrant une automatisation poussée.
-
Qualité des livrables (S2) :
- Le Jupyter Notebook présente des graphiques interactifs avec annotations et commentaires explicatifs, soulignant la rigueur analytique.
- La présentation orale a été illustrée par des extraits de code en direct, assurant une démonstration concrète et engageante.
Points forts
- Livrables visuellement soignés : diagrammes, couleurs, légendes, commentaires clairs.
- Approche transversale : on ne se contente pas de modéliser, on automatise et on analyse en profondeur.
- Intégration cohérente entre SQL et Python : chaque résultat statistique est directement lié à une interrogation SQL.
Axes d’amélioration
- Renforcer l’interactivité des graphiques Python (ex. Dash/Plotly) pour rendre la restitution plus dynamique.
- Ajouter une section “UX/UI” pour décrire l’ergonomie de l’outil d’administration de la base (même si non demandé, cela valoriserait l’expérience utilisateur).
- Documenter davantage les choix de schéma relationnel dans un README détaillé, afin de faciliter la reprise par un autre développeur.